
Программная конвейеризация
Software Pipelining (loop pipelining) – конвейеризация циклов. Это преобразование, призванное использовать способность процессора к параллельному вычислению для операций, находящихся на различных итерациях цикла.
Здесь мы расскажем об алгоритме итеративной модульной планировки (Iterative Modulo Scheduling), впервые описанном в [17].
В качестве примера рассмотрим вот такой цикл: for i O1: a[i]=i*i O2: b[i]=a[i]*b[i-1] O3: c[i]=b[i]/n O4: d[i]=b[i]%n
Для удобства цикл представлен с помощью графа зависимости по данным (DDG) следующего вида:
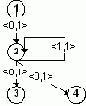
Где в кружках стоят номера инструкций, а каждое ребро между инструкциями i и j помечено парой чисел <d,p>. Ребро означает:
- j зависит от значения, вычисленного i инструкцией p итераций цикла назад
- как минимум d тактов должно пройти после выполнения соответствующего экземпляра i, чтобы можно было выполнить j
После программной конвейеризации данный цикл может иметь следующий вид:
| Итерации | ||||
| Время (такты) | Пролог | 1 | ||
| 2 | 1 | |||
| Ядро (n-3 раз) | 3,4 | 2 | 1 | |
| Эпилог | 3,4 | 2 | ||
| 3,4 |
Как видно из таблицы, после преобразования цикл разбивается на три стадии: пролог, эпилог и ядро. В данном случае время между началом последовательных итераций ядра – один такт. Вообще задержка между началом последовательных итераций называется основным интервалом (initiation interval, размер ядра получаемого цикла) и обычно обозначается как II.
Описываемый здесь алгоритм итеративный. Он пытается построить план (schedule) для значения основного интервала II, в случае неудачи увеличивая II на 1. Таким образом, очевидно, что скорость работы алгоритма непосредственно зависит от того, насколько удачно было выбрано начальное значение основного интервала. На выборе этого значения остановимся подробнее.
Для начала построим процедуру оценки минимального значения основного интервала II, обозначив её как MII.
delay(c) = ?i?C di - суммарная задержка по зависимостям данных для цикла c
distance(c) = ?i?C Pi - суммарная дистанция в итерациях для цикла c
uses(r) - количество использований ресурса c за одну итерацию цикла
units(r) - число функциональных модулей типа c
Где C - естественный цикл на графе, являющимся транзитивным замыканием исходного графа зависимости по данным, G - множество всех таких циклов, а R-множество ресурсов.
Нижняя оценка величины основного интервала может быть получена двумя способами. Во-первых, можно оценить максимальную задержку по зависимостям по данным для каждого из естественных циклов на графе:
RecMII = maxc?G delay(c)/distance(c)
Во-вторых, задержку можно оценить исходя из предельной загруженности функциональных модулей по каждому из ресурсов:
RecMII = maxr?R uses(r)/units(r)
Разумно взять наибольшую из полученных выше оценок за начальную величину основного интервала:
MII=max(RecMII, ResMII)
Сам алгоритм выглядит следующим образом:
procedure modulo_schedule(budget_ratio) compute MII; II:=MII; budget:=budget_ratio*количество инструкций; while не найдено подходящего расписания do iterative_schedule(II, budget); II:=II+1;
Где budget_ratio – количество возвратов в переборе перед тем, как переходить к следующему значению II. Непосредственно сам перебор с возвратом происходит в процедуре
iterative_schedule:
procedure iterative_schedule (II, budget); compute height-based priorities; while есть неспланированные операции и budget > 0 do op:=операция с наивысшим приоритетом; min:=наиболее раннее время для операции op; max:=min+II-1; t:=find_slot(op,min,max); выставить операцию op в момент t переместить все операции, имеющие конфликт с op, обратно в список неспланированных команд; budget:=budget-1;
На каждом шаге выбирается инструкция с максимальным приоритетом. Возможны различные подходы к вычислению приоритета инструкции H(i), например:
H(i)=0, если i не имеет последователей, иначе
H(i) = maxk?succ(i) H(k) + latency(i,k) - II*distance(i,k)
Непосредственно временной слот, в который будет помещена конкретная инструкция j, ограничен снизу уже расставленными предшественниками k:
time(j) ? time(k)+latency(k,j)-II*distance(k,j)
Процедура find_slot находит минимальный временной слот между min и max, такой, что операция op может быть размещена без конфликтов по ресурсам. Отметим, что выбранный слот может вызывать конфликты по ресурсам. Таким образом, размещение некоторых более ранних операций можно откатить и повторить заново.
procedure find_slot(op, min, max); for t:=min to max do if op не имеет конфликтов в моменте времени t return t; if op ещё не встречалась or min > предыдущее спланированное время для op return min; else return 1 + предыдущее спланированное время для op;
Для проверки конфликтов по ресурсам используется таблица резервирования. Высота этой таблицы равна II. Если ресурс r используется в момент времени t, то в таблице помечается ячейка [r, t mod II], поэтому эту таблицу ещё называют модульной таблицей резервирования (modulo reservation table, MRT).
Приведённый здесь алгоритм лишь один из представителей целого класса. Он может учитывать множество дополнительных особенностей используемой архитектуры, такой как предикатное исполнение. Более подробно обзор различных подходов к программной конвейеризации циклов может быть найден в [16].